

IT owes its existence as a professional discipline to companies seeking to use data to gain a competitive edge. Today, organizations are awash in data, but the technology to process and analyze it often struggles to keep up with the deluge of real-time data. It isn’t just the sheer volume of data that is proving to be a challenge, it’s also the widely varied data types.
An explosion in unstructured data, for example, has proved to be particularly challenging for information systems that have traditionally been based on structured databases. This has sparked the development of new algorithms based on machine learning (ML) and deep learning. In turn, this has led to a need for organizations to either buy or build systems and infrastructure for ML, deep learning and AI workloads.
While the interest in ML and deep learning has been building for several years, new technologies such as ChatGPT and Microsoft Copilot fuel interest in enterprise AI applications. IDC predicts that by 2025, 40% of Global 2000 organizations’ IT budgets will be spent on AI-related initiatives as AI will lead as the motivator of innovation.
Enterprises undoubtedly build many of their AI- and ML-based applications in the cloud by using high-level ML and deep learning services like Amazon Comprehend or Azure OpenAI Service. But the massive amount of data required to train and feed AI algorithms, the prohibitive costs of moving data to — and storing it in — the cloud, and the need for real-time (or near-real-time) results, means many enterprise AI systems are deployed on private, dedicated systems.
Many such systems reside in the enterprise data center. However, AI systems also exist at the edge, necessitated by the requirement for such systems to reside near the systems that generate the data that organizations must analyze.
In preparing for an AI-enhanced future, IT must grapple with many architectural and deployment choices. Chief among these is the design and specification of AI-accelerated hardware clusters. One promising option, due to their density, scalability and flexibility, is hyper-converged infrastructure (HCI) systems. While many elements of AI-optimized hardware are highly specialized, the overall design bears a strong resemblance to more ordinary hyperconverged hardware. In fact, there are HCI reference architectures that have been created for use with ML and AI.
AI requirements and core hardware elements
Machine and deep learning algorithms feed on data. Data selection, collection and preprocessing, such as filtering, categorization and feature extraction, are the primary factors contributing to a model’s accuracy and predictive value. Therefore, data aggregation — consolidating data from multiple sources — and storage are significant elements of AI applications that influence hardware design.
The resources required for data storage and AI computation don’t typically scale in unison. So, most system designs decouple the two, with local storage in an AI compute node designed to be large and fast enough to feed the algorithm.
Machine and deep learning algorithms require a massive number of matrix multiplication and accumulation floating-point operations. The algorithms can perform the matrix calculations in parallel, which makes ML and deep learning similar to the graphics calculations like pixel shading and ray tracing that are greatly accelerated by GPUs.
However, unlike CGI graphics and imagery, ML and deep learning calculations often don’t require double-precision (64-bit) or even single-precision (32-bit) accuracy. This enables a further boost in performance by reducing the number of floating-point bits used in the calculations. Early deep learning research used off-the-shelf GPU accelerator cards for the past decade. Now, companies like Nvidia have a separate product line of data center GPUs tailored to scientific and AI workloads.
More recently, Nvidia announced a new line of GPUs that are specifically designed to boost generative AI performance on desktops and laptops. The company has also introduced a line of purpose-built AI supercomputers.
System requirements and components
The system components most critical to AI performance are the following:
- CPU. Responsible for operating the VM or container subsystem, dispatching code to GPUs and handling I/O. Current products use the popular fifth-generation Xeon Scalable Platinum or Gold processor, although systems using fourth-generation (Rome) AMD Epyc CPUs are becoming more popular. Current-generation CPUs have added features that significantly speed up ML and deep learning inference operations, making them suitable for production AI workloads utilizing models previously trained using GPUs.
- GPU. Handles ML or deep learning training and inferencing — the ability to automatically categorize data based on learning. Nvidia offers purpose-built accelerated servers through its EGX line. The company’s Grace CPU was also designed with AI in mind and optimizes communications between the CPU and GPU.
- Memory. AI operations run from GPU memory, so system memory isn’t usually a bottleneck, and servers typically have 512 GB or more of DRAM. GPUs use embedded high bandwidth memory modules. Nvidia refers to these modules as Streaming Multiprocessors, or SMs. According to Nvidia, the “Nvidia A100 GPU contains 108 SMs, a 40 MB L2 cache, and up to 2039 GB/s bandwidth from 80 GB of HBM2 memory.”
- Network. Because AI systems are often clustered together to scale performance, systems tend to be equipped with multiple 10 GbE or 40 GbE ports.
- Storage IOPS. Moving data between the storage and compute subsystems is another performance bottleneck for AI workloads. So, most systems use local NVMe drives instead of SATA SSDs.
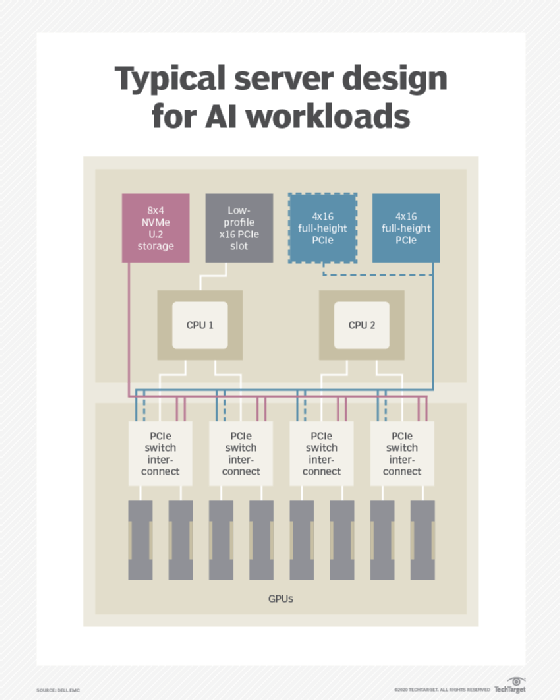
GPUs have been the workhorse for most AI workloads, and Nvidia has significantly improved its deep learning performance through features such as Tensor Core and Multi-instance GPUs (to run multiple processes in parallel and NVLink GPU interconnects).
Enterprises can use any HCI or high-density system for AI by choosing the right configuration and system components. However, many vendors offer products targeted to ML and deep learning workloads. The following is a representative summary of primary ML and deep learning system parameters from leading vendors:
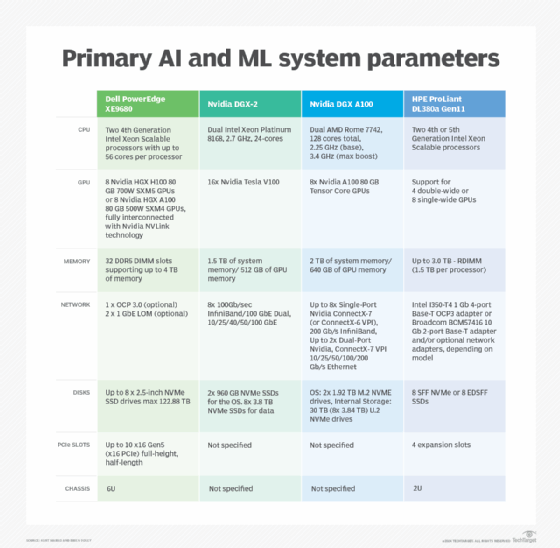
Editor’s note: This article on infrastructure for machine learning and AI requirements was originally written by Kurt Marko in 2020, and then updated and expanded by Brien Posey in 2024. This article was updated to include more timely information on ML, AI and system requirements. New vendor information has been provided by the author based on primary ML and deep learning system parameters of leading companies.
Kurt Marko was a longtime TechTarget contributor who passed away in January 2022. He was an experienced IT analyst and consultant, a role in which he applied his broad and deep knowledge of enterprise IT architectures. You can explore all the articles he authored for TechTarget on his contributor page.
Brien Posey is a 15-time Microsoft MVP with two decades of IT experience. He has served as a lead network engineer for the U.S. Department of Defense and as a network administrator for some of the largest insurance companies in America.
link